
En este post aprenderemos a monitorizar nuestras máquinas y servicios con Nagios. Gracias a este software, recibiremos alertas detalladas y accionables sobre nuestra insfraestructura.
- Qué es Nagios.
- Conceptos básicos para trabajar con Nagios.
- Escenario sobre el cual trabajaremos en este post.
- Instalación de Nagios.
- Monitorización de servicios y equipos.
- Comprobar el mapa de nuestros equipos y servicios.
- Comprobación de funcionamiento y notificaciones.
- Conclusiones.
Qué es Nagios.
Nagios es software usado para monitorizar sistemas, servicios, redes e infraestructura. Envía alertas en caso de problemas, y notificaciones cuando el problema ha sido resuelto.
Al contrario que otras soluciones comerciales como SolarWinds, Nagios es open source y gratis con la posibilidad de contratar soporte comercial.
Conceptos básicos para trabajar con Nagios.
Nagios puede obtener información de los recursos a monitorizar de dos formas diferentes, siendo capaz de usar ambas a la vez:
-
A través del agente de Nagios: Comprobaciones regulares iniciadas por los mismos clientes y enviadas al servidor, requiere instalación del agente en los equipos a monitorizar. La principal ventaja es la flexibilidad a la hora de desplegar addons o comprobaciones personalizadas.
-
Agentless (“sin agente”): El servidor Nagios utiliza tecnologías como WMI y SNMP para realizar comprobaciones sobre los recursos monitorizados. Su principal ventaja es la reducción en complejidad del despliegue, y la centralización de la configuración en el servidor Nagios.
Posibles estados y flujo de transición entre estados de un servicio o recurso monitorizados.
El estado de un servicio o recurso se determina a través de dos componentes:
- El estado del servicio o recurso: OK, WARNING, UP, DOWN...
- El tipo de estado en el que se encuentra el servicio.
Hay dos tipos de estado en Nagios: soft y hard. Para prevenir falsas alarmas provocadas por problemas transitorios, Nagios realiza un número de reintentos antes de considerar que un problema es “real”. El número de reintentos se define en la variable max_check_attempts, y cuando se supera el límite especificado el problema pasa de soft a hard. De la misma forma, para considerar un problema como solucionado se efectúa el mismo número de comprobaciones antes de transicionar el estado de hard a solucionado.
Salvo que hayamos especificado lo contrario, las notificaciones sólo se envían cuando el servicio entra en estado hard down.
Nagios nos permite escribir nuestro propio script que determine la acción a tomar según el estado del recurso monitorizado. Por ejemplo, si un servidor web está en estado soft down y se ha reintentado 4 veces la comprobación, podríamos iniciar el despliegue de otro servidor web anticipándonos a la posible caída del servicio.
Los estados se describen en mucho más detalle en la web del programa (en inglés).
Qué significa que un servicio o recurso está “flapping”.
Flapping es una palabra inglesa que describe el aleteo frenético de un pájaro. Se utiliza habitualmente para describir el intento de mantener el vuelo en condiciones adversas.
Volviendo a Nagios: cuando un servicio cambia rápidamente entre disponible y algún estado de error, se considera que el servicio está flapping. Esto puede deberse a circunstancias transitorias perfectamente normales (por ejemplo, alta carga de CPU durante operaciones específicas en la base de datos que no afectan al funcionamiento de la aplicación), y puede generar una lluvia de notificaciones sobre un falso problema.
La manera de mitigar el problema es observar el comportamiento habitual del servicio o recurso y configurar max_check_attempts a un valor suficientemente alto para que estas circunstancias de funcionamiento correctas no generen falsas alertas. Dado que cada entorno y condiciones de uso son diferentes, los ajustes por defecto de detección de flapping de Nagios pueden ser inadecuados para nuestra infraestructura.
Escenario sobre el cual trabajaremos en este post.
Tenemos 3 máquinas virtuales en la misma red, con el sistema operativo Debian en su versión 8 (Jessie).
- nagiosHost: 192.168.100.1, actuará de host para Nagios. Tendrá instalado un servidor SSH y una base de datos MongoDB.
- servidorLamp: 192.168.100.2, tendrá instalado una stack LAMP.
- escritorioUsuario: 192.168.100.3, es un cliente Debian estándar.
Este escenario está recogido en este Vagrantfile, incluyendo el despliegue de los servicios y la configuración del servidor Nagios y los clientes.
Instalación de Nagios.
sudo DEBIAN_FRONTEND=noninteractive apt-get -y install nagios-plugins nagios3 nagios-nrpe-pluginnrpe-server es un agente instalado en las máquinas cliente que se encarga de comunicar con el host Nagios para informar de estado y ejecución de comandos de forma remota. Estos comando pueden ser definidos de forma manual por el administrador, aunque un conjunto de comandos de uso frecuente se encuentra pre-empaquetado en nagios-plugins. Más adelante veremos cómo instalar plugins adicionales para monitorizar MongoDB, y cómo definir nuestros propios comandos (usaremos como ejemplo comprobar si existen procesos zombie).
Para poder forzar chequeos sobre los servicios y hosts de forma manual, debemos realizar el siguiente cambio en el archivo /etc/nagios3/nagios.cfg
check_external_commands = 1También debemos cambiar el usuario y modo de dos directorios para permitir que el servicio de nagios pueda escribir archivos temporales en ellos. En caso de no hacerlo, recibiremos un mensaje de error de tipo Could not stat() command file ‘/var/lib/nagios3/rw/nagios.cmd’.
Este cambio lo implementaremos a través del gestor de paquetes, para que se preserve en caso de actualizaciones.
dpkg-statoverride --update --add nagios www-data 2710 /var/lib/nagios3/rw
sudo dpkg-statoverride --update --add nagios nagios 751 /var/lib/nagios3Para habilitar el acceso web, creamos un usuario llamado ‘nagiosadmin’ con contraseña ‘nagios’ y reiniciamos el servicio:
htpasswd -b -c /etc/nagios3/htpasswd.users nagiosadmin nagios
service nagios3 restartMonitorización de servicios y equipos.
Los servicios están asociados a equipos. Para poder añadirlos debemos instalar el agente de monitorización en él. Realizaré este proceso en nagiosHost, siendo idéntico en servidorLamp y en escritorioUsuario.
Instalación del agente de monitorización
DEBIAN_FRONTEND=noninteractive sudo apt-get install -y --force-yes build-essential nagios-nrpe-server nagios-pluginsHabilitamos la ejecución de comandos de forma remota.
sudo sed -i "s/.*dont_blame_nrpe.*/dont_blame_nrpe = 1/" /etc/nagios/nrpe.cfgY damos permiso al servidor Nagios para ejecutarlos.
sudo sed -i "s/.*allowed_hosts.*/allowed_hosts = 127.0.0.1 192.168.100.1/" /etc/nagios/nrpe.cfgAñadir dispositivos a la lista de monitorización.
El directorio conf.d es procesado en su totalidad al construir la configuración final. Podemos almacenar la configuración en archivos cfg con diferentes nombres que respondan a la organización logica de nuestra infraestructura, sin tener que seguir el patrón establecido en este post.
Los siguientes pasos deben realizarse en el servidor Nagios, que en este escenario nagiosHost.
/etc/nagios3/conf.d/nodes.cfg contiene la lista de equipos a monitorizar. En nuestro caso, el archivo tendrá el siguiente contenido.
define host{
use generic-host
host_name nagiosHost
alias nagiosHost
address 127.0.0.1
}
define host{
use generic-host
host_name servidorLamp
alias servidorLamp
address 192.168.100.2
}
define host{
use generic-host
host_name escritorioUsuario
alias escritorioUsuario
address 192.168.100.3
}Los dispositivos se organizan en grupos, de forma que las politicas de monitorización puedan aplicarse a todos los equipos que pertenezcan a una de esas categorias. Estas definiciones serán guardadas en /etc/nagios3/conf.d/hostgroups_nagios2.cfg.
define hostgroup {
hostgroup_name all
alias All Servers
members *
}
define hostgroup {
hostgroup_name debian-servers
alias Debian GNU/Linux Servers
members nagiosHost,escritorioUsuario
}
define hostgroup {
hostgroup_name http-servers
alias HTTP servers
members nagiosHost, servidorLamp
}
define hostgroup {
hostgroup_name ssh-servers
alias SSH servers
members nagiosHost
}
define hostgroup {
hostgroup_name mongo-servers
alias Mongo servers
members nagiosHost
}Monitorizando servicios.
/etc/nagios3/conf.d/services_nagios2.cfg contiene las definiciones de los servicios a monitorizar.
define service {
hostgroup_name http-servers
service_description HTTP
check_command check_http
use generic-service
notification_interval 0 ; set > 0 if you want to be renotified
}
define service {
hostgroup_name ssh-servers
service_description SSH
check_command check_ssh
use generic-service
notification_interval 0 ; set > 0 if you want to be renotified
}/etc/nagios3/conf.d/nagiosHost.cfg
Aquí incluiremos definiciones de servicios para monitorizar los usuarios que se loguean en la máquina, el número de procesos y la carga de cpu.
define service{
use generic-service
host_name nagiosHost
service_description Current Users
check_command check_users!20!50
}
define service{
use generic-service
host_name nagiosHost
service_description Total Processes
check_command check_procs!250!400
}
define service{
use generic-service
host_name nagiosHost
service_description Current Load
check_command check_load!5.0!4.0!3.0!10.0!6.0!4.0
}/etc/nagios3/conf.d/escritorioUsuario.cfg
De la misma forma, aquí incorporamos la definicion de procesos zombie.
define service{
use generic-service ; Name of service template to use
host_name escritorioUsuario
service_description Zombie processes
check_command check_host_for_zombies
}Dado que este es un check personalizado, debemos definirlo de forma explícita. Lo haremos en la siguiente sección.
Añadiendo chequeos de servicio personalizados.
Los chequeos personalizados se definen en dos partes: Una declaración obligatoria en el servidor de Nagios, y una declaración opcional en el dispositivo monitorizado.
En el servidor de Nagios definimos el comando que se va a ejecutar desde el mismo servidor.
En el dispositivo monitorizado, definimos el comando que va a ejecutarse desde el mismo dispositivo monitorizado.
Si necesitamos obtener información acerca del estado de un dispositivo, y esta información solo puede obtener mediante la ejecución de código en el mismo; debemos declarar ambos comandos.
Por ejemplo, en este escenario queremos comprobar la existencia de procesos zombie y la disponibilidad del servicio de MongoDB. Para poder acceder a la lista de procesos de la máquina monitorizada, debemos ejecutar código en la máquina. Mientras que si queremos comprobar que el servidor MongoDB está aceptando conexiones, podemos comprobarlo desde el servidor Nagios iniciando una nueva conexión como si fuésemos otro cliente cualquiera.
Comprobando la existencia de procesos zombie.
Servidor Nagios.
/etc/nagios3/commands.cfg
define command {
command_name check_host_for_zombies
command_line $USER1$/check_nrpe -H $HOSTADDRESS$ -c check_zombies
}Dispositivo monitorizado.
/etc/nagios/nrpe_local.cfg
command[check_zombies]=/usr/lib/nagios/plugins/check_procs -w 0 -s Z+Instalando plugins adicionales para monitorizar otros servicios.
Para comprobar el estado del servicio de MongoDB en nagiosHost, vamos a utilizar nagios-plugin-mongodb. El proceso es muy parecido a añadir un chequeo personalizado; la única diferencia es que al no tener ya disponible el comando check_mongodb tenemos que instalarlo previamente.
Instalando nagios-plugin-mongodb
Dado que el plugin está programado en Python, el proceso de instalación es muy sencillo. Clonamos el repositorio git del plugin en el servidor de nagios, instalamos los requisitos y a por último el conector python de MongoDB.
cd /usr/lib/nagios/plugins
git clone git://github.com/mzupan/nagios-plugin-mongodb.git
pip install requirements
python -m pip install pymongoAñadimos la definición del servicio a la configuración. Dado que es posible que añadiésemos servidores de MongoDB adicionales en un futuro, definimos el servicio como aplicable al grupo de hosts mongo-servers.
/etc/nagios3/conf.d/services_nagios2.cfg
define service {
use generic-service
hostgroup_name mongo-servers
service_description Mongo Connect Check
check_command check_mongodb!connect!27017!2!4
contact_groups admins
}commands.cfg
define command {
command_name check_mongodb
command_line $USER1$/nagios-plugin-mongodb/check_mongodb.py -H $HOSTADDRESS$ -A $ARG1$ -P $ARG2$ -W $ARG3$ -C $ARG4$
}La sintáxis de check_mongodb.py está explicada en la documentación, y cada plugin que instalemos suele tener su propia sintáxis.
Configurando las notificaciones por email.
Nagios tiene la capacidad de enviar notificaciones de email a grupos de contactos, que obviamente contienen contactos. Vamos a crear un contacto de nombre root que pertecenerá al grupo de contactos admins.
/etc/nagios3/conf.d/contacts_nagios2.cfg contendrá la lista de contactos. También contendrá el comando que se ejecutará al realizar el envio de notificaciones, que definiremos más adelante.
define contact{
contact_name root
alias Root
service_notification_period 24x7
host_notification_period 24x7
service_notification_options w,u,c,r,f
host_notification_options d,r,f
service_notification_commands notify-service-by-email
host_notification_commands notify-host-by-email
email correo@servidor.com
}Y /etc/nagios3/conf.d/contact_groups_nagios2.cfg contendrá la lista de grupos, junto con los miembros de cada grupo.
define contactgroup {
contactgroup_name admins
alias Level 7 Administrators
members root
}Ahora añadimos a cada servicio los grupos que deben ser notificados en caso de incidencia usando la variable contact_groups. Por ejemplo, para el servicio SSH se haría así.
define service {
hostgroup_name ssh-servers
service_description SSH
check_command check_ssh
use generic-service
notification_interval 0 ; set > 0 if you want to be renotified
contact_groups admins
}Personalizando el contenido de los emails y los medios de envío.
En este post voy a utilizar sendemail para enviar correo a través del servidor SMTP de GMail. Lo instalamos en nagiosHost con la siguiente línea
sudo apt-get install sendemailModificamos el comando de envío de correo en commands.cfg para que se adecúe a la sintaxis del comando sendemail.
define command{
command_name notify-host-by-email
command_line /usr/bin/printf "%b" "***** Nagios *****\n\nNotification Type: $NOTIFICATIONTYPE$\nHost: $HOSTNAME$\nState: $HOSTSTATE$\nAddress: $HOSTADDRESS$\nInfo: $HOSTOUTPUT$\n\nDate/Time: $LONGDATETIME$n" | /usr/bin/sendEmail -xu $USER4$ -xp $USER5$ -t $CONTACTEMAIL$ -f $CONTACTEMAIL$ -o tls=auto -s smtp.gmail.com -u "** $NOTIFICATIONTYPE$ Host Alert: $HOSTNAME$ is $HOSTSTATE$ **" -m "***** Nagios *****\n\nNotification Type: $NOTIFICATIONTYPE$\nHost: $HOSTNAME$\nState: $HOSTSTATE$\nAddress: $HOSTADDRESS$\nInfo: $HOSTOUTPUT$\n\nDate/Time: $LONGDATETIME$\n"
}
define command{
command_name notify-service-by-email
command_line /usr/bin/printf "%b" "***** Nagios *****\n\nNotification Type: $NOTIFICATIONTYPE$\n\nService: $SERVICEDESC$\nHost: $HOSTALIAS$\nAddress: $HOSTADDRESS$\nState: $SERVICESTATE$\n\nDate/Time: $LONGDATETIME$\n\nAdditional Info:\n\n$SERVICEOUTPUT$" | /usr/bin/sendEmail -s smtp.gmail.com -xu $USER4$ -xp $USER5$ -t $CONTACTEMAIL$ -f $CONTACTEMAIL$ -u "** $NOTIFICATIONTYPE$ Service Alert: $HOSTALIAS$/$SERVICEDESC$ is $SERVICESTATE$ **" -m "***** Nagios *****\n\nNotification Type: $NOTIFICATIONTYPE$\n\nService: $SERVICEDESC$\nHost: $HOSTALIAS$\nAddress: $HOSTADDRESS$\nState: $SERVICESTATE$\n\nDate/Time: $LONGDATETIME$\n\nAdditional Info:\n\n$SERVICEOUTPUT$"
}Podríamos personalizar la línea de comando para incluir otros medios de notificación. Por ejemplo, podemos añadir notificaciones por SMS a través de Twilio o mensajes por Slack.
Añadimos las definiciones de las variables $USER4 y $USER5, que corresponden respectivamente a nuestro usuario y contraseña de GMail, en el archivo /etc/nagios3/resource.cfg.
$USER4$=usuario
$USER5$=contraseñaAVISO: Estos datos se almacenan en texto plano. Por seguridad, es conveniente generar credenciales propias para Nagios. En el caso de GMail, esto puede hacerse activando autenticación en dos pasos y generando una contraseña de aplicación.
Comprobar el mapa de nuestros equipos y servicios.
A través de la interfaz web, en la sección “Map” podemos ver una representación gráfica de nuestra infraestructura.
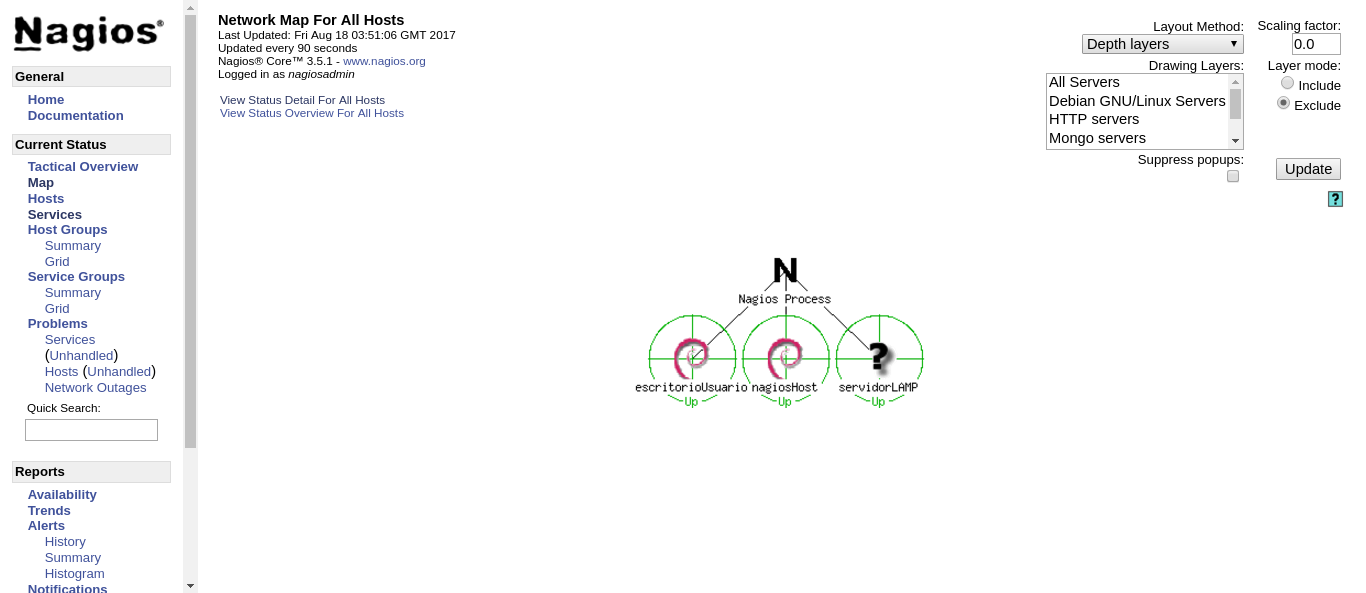
Si hacemos click en cualquiera de los equipos, podemos ver a simple vista su estado de salud.
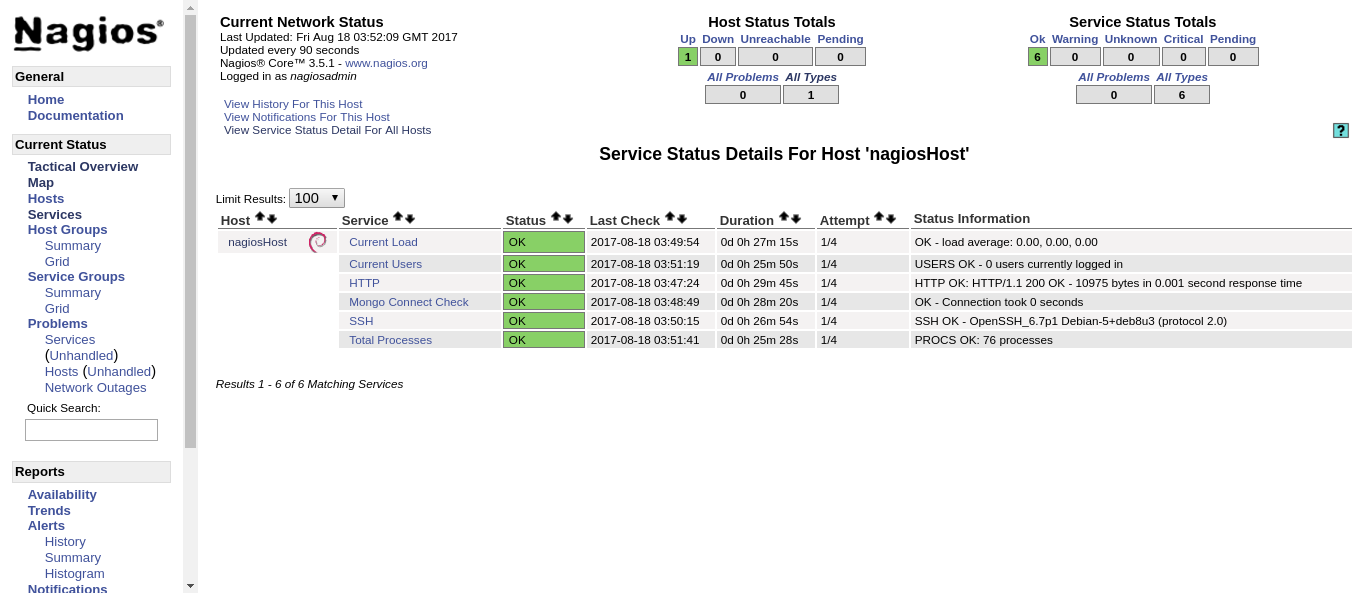
Comprobación de funcionamiento y notificaciones.
Equipo fuera de línea.
Vamos a simular un fallo apagando la máquina escritorioUsuario.
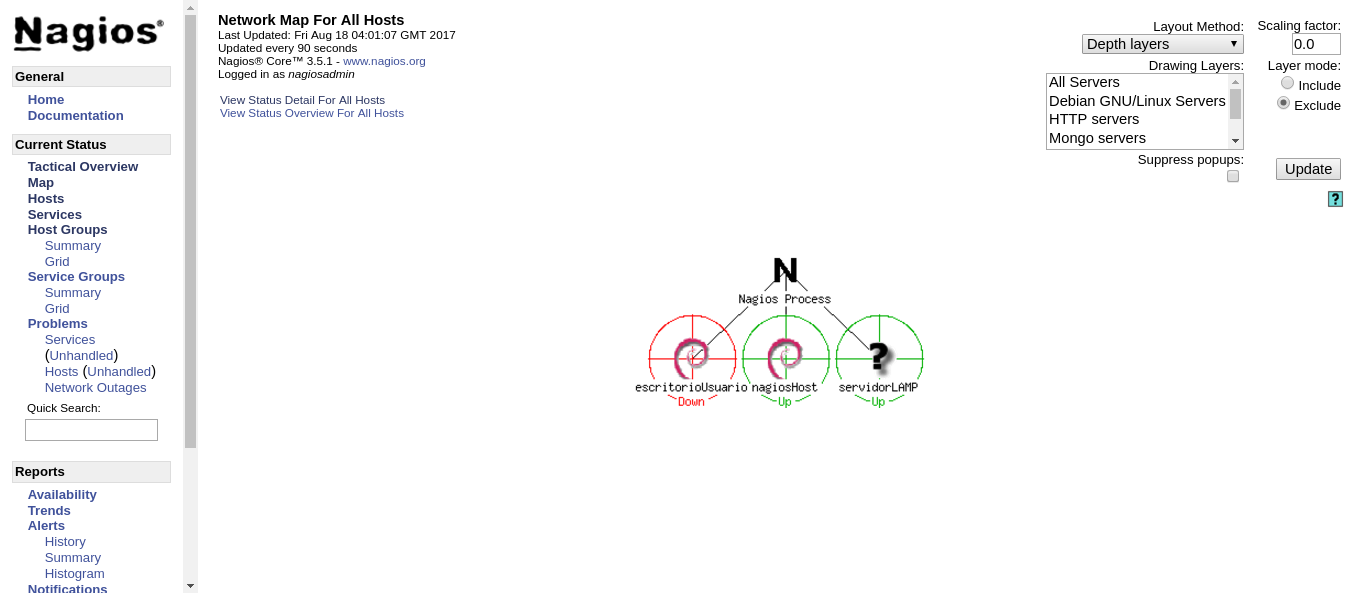
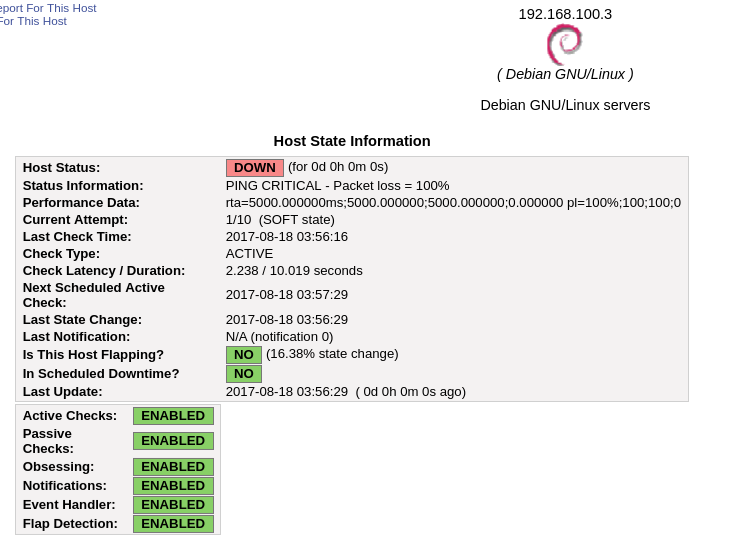
Pasado el número de reintentos especificado la máquina pasa a estar fuera de línea oficialmente y se envía la notificación correspondiente.
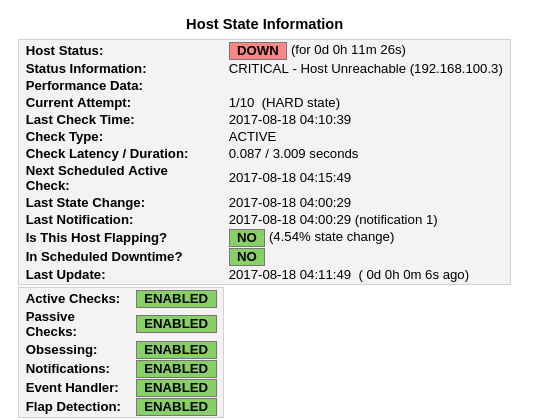
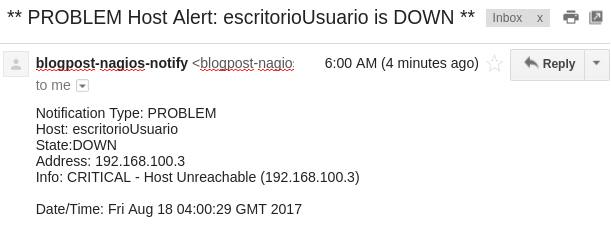
Tras volver a encender la máquina, vemos que Nagios detecta que se ha resuelto el problema, y nos envía una notificación al respecto.

Proceso Zombie.
Generamos un proceso zombie usando la siguiente línea en la terminal de escritorioUsuario.
sleep 1 & exec /bin/sleep 600Y observamos que Nagios lo detecta, y nos envia el email correspondiente.
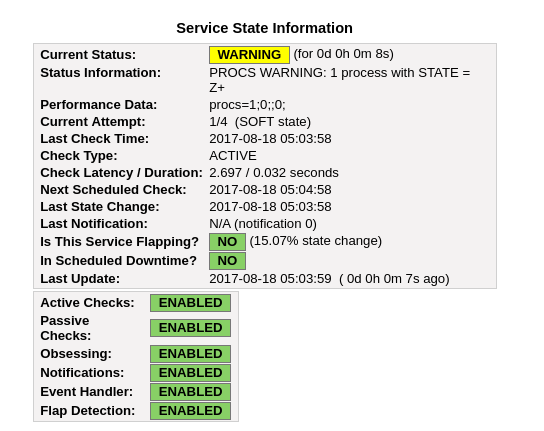
Base de datos MongoDB fuera de línea.
Si detenemos el servicio de MongoDB, comprobamos que efectivamente falla el chequeo de Nagios y nos notifica adecuadamente.
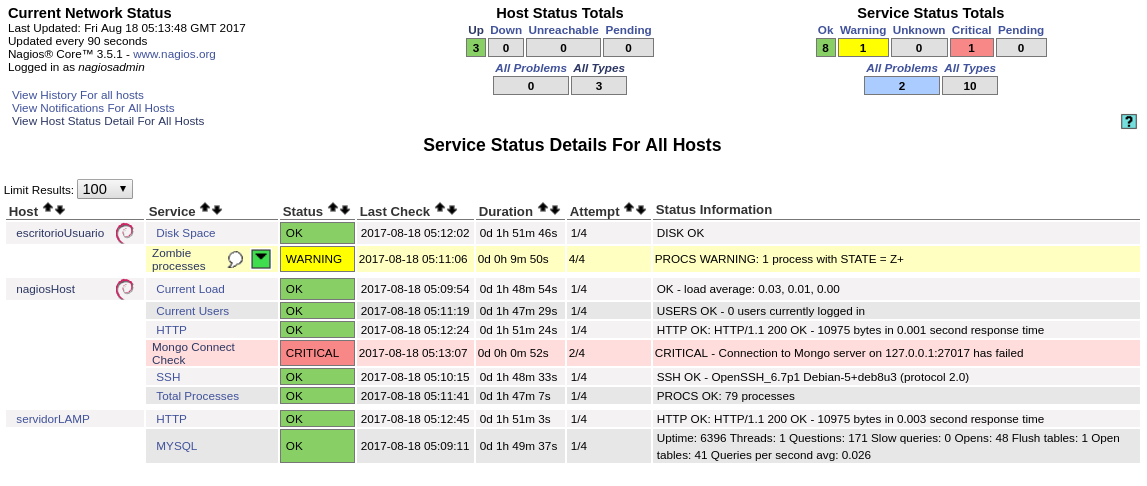
Conclusiones.
Es de vital importancia que conozcamos potenciales problemas de nuestra infraestructura antes de que nuestros clientes nos lo comuniquen.
Nagios nos permite condensar toda la información sobre el estado de nuestro despliegue en una única pantalla, fácilmente comprensible en un vistazo. La inversión de tiempo que requiere su configuración merece la pena, dado que nos aporta la tranquilidad de saber que nuestra infraestructura está sana, y que si eso cambiase seremos los primeros en saberlo.